“Expert Hadoop Administration: Managing, Tuning, and Securing Spark, YARN, and HDFS”, by Addison Wesley

HDFS
- Fault tolerant with replication of blocks
- Clients talk to data nodes directly
- Data never travels through NameNode
- HDFS is network/disk bound
- spark/hive ram bound
- for network look for deep-buffering switches in racks, instead of low latency
- data is replicated 3x, named node is replicated by standby/secondary named node
- NB: need large disk, need high network bandwidth
- NB: 3x replication is only within a cluster. if cluster goes down, so all of it
- /etc/hosts mapping dns to ip
- for cluster, just ssh and start what daemons you need to start (name node, resource manager, etc.)
- Gateway Machine - don’t run DataNode, NameNode, etc. rather install Pig, Sqoop clients, Flume agents, and other applications.
- users Linux user as user for HDFS
- does not have ACL
- does not have AuthN, use Kerbos
- can short-curircuit local reads to read from file system instead of network
- has “GLACIER”-like storage policies = you define what kind of storage files are stored in (expensive-fast or cheap-slow)
- if file is smaller than block, it takes whole block size
- if not critical files, can make replication factor to two
- to balance reads for hot-files can increase replicas to 4+
- space quota = how much space can be used for dir
- names quota = how many files can be in dir
- run balanced to move blocks
hdfs balancer - HDFS snapshots = blocks of data not copied, only metadata
- block level compression = can decompress piece of file without reading whole file
- small files HDFS problem = need at least block size
- ORC = Optimized Row Columnar format = splits files horizontally into groups, and stores vertically by column
- HAR = Hadoop Archive
NameNode
- No actual data
- Stores metadata
- Filepaths
- Mapping from Files to Blocks
- Mapping which DataNodes has Blocks (data nodes send this data)
- Can have Stand-by (does log compaction, can be switched to for resiliency)
- Can have Secondary (does log compaction)
- Has monotonically increasing generation timestamp for each block
- Keeps state of cache in all nodes for performance
- opening/closing files and dirs
- need to run topology.py and configure rack awareness
fsimagefile with compressed + edit log since thenhdfs dfsadmin -fetchImage /tmp- DataNode daemons connect as last step to NameNode on startup to send what they have

DataNode
- Actual data in blocks
- Stores in local file system
- No awareness of HDFS files, stores only blocks
- Replicas written asynchronously. Client send block only once, from there DataNode sends to others.
- Data replicated with rack awareness (2 on same rack, 1 on other rack)
- DataNode stores checksum for block, when block is read it is verified
YARN, Hadoop
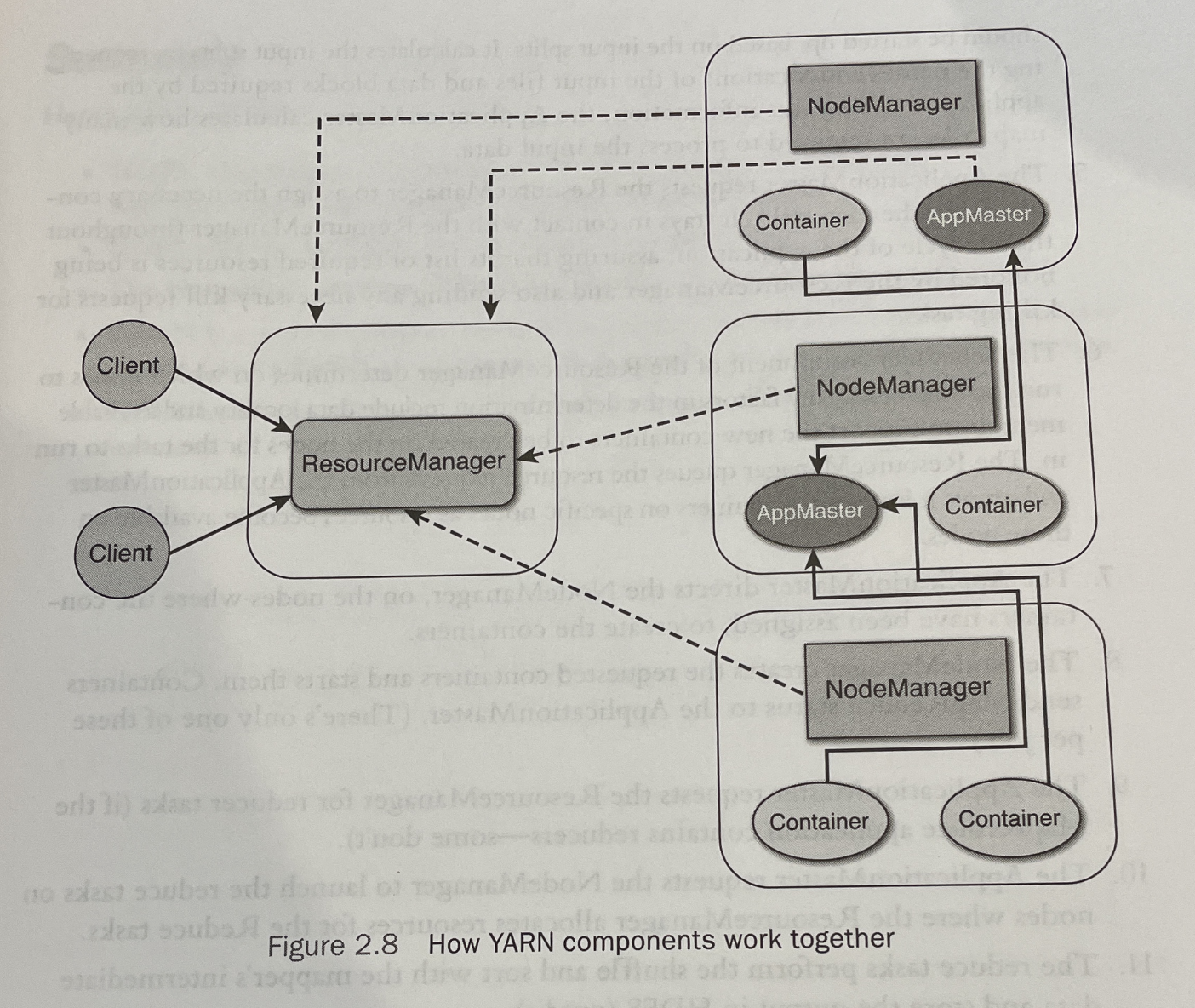
- ResourceManager = allocating cluster resources to applications, scheduling
- ApplicationManager = coordinates execution of single application
- NodeManager = YARN worker, runs YARN containers
- Reading from RAM make large speedup
- Avoiding shuffles makes large speedup
- Capacity Scheduler
- Fair Scheduler = same as capacity, uses priority inside pools, preemption
60TB by 256MB blocks -> 250,000 map tasks- Ideally in separate network, as not secure
- Gateway node = same network, used for applications and UIs
- Data Gateway = connections to RDBMs
- Kerbeos is complex. Something like getting auth tokens using passwords. Can connect to Directory.
- to control number of containers, set memory for a container
- “speculative execution” = start execution if hangs for too long even if not failed, relying on idempotence
- map task = read, map, spill, merge,
.._m_.. - reduce task = shuffle, reduce, write,
.._r_.. - Benchmark with
TestDFSIO

CLI
$ jps # java processes
$ hdfs dfs -ls / # like ls but for HDFS
$ pdsh #shell for multi hosts at same time
$ hdfs dfsadmin -report # stats about HDFS
$ hdfs fds -copyFromLocal file.txt /input/file
$ hdfs dfs -get /out/result
$ hdfs dfs -cat /out/result
$ hdfs dfsadmin -printTopology # racks nodes location
$ hdfs fsck / # show number of data nodes and racks
$ hdfs dfsadmin -report
$ hdfs dfs -df # free space
$ hdfs dfs -du -h / # usage
$ hdfs dfs -test -e /abc # file exists
$ ethtool eth0 # speed of network of machine
$ hdfs storagepolicies -listPolicies
$ hdfs dfs -put
$ hdfs dfs -get
$ hdfs dfs -mv
$ hdfs dfs -tail
$ hadoop distcp srcdir destdir # copy between clusters!
$ yarn application -movetoqueue appID -queue myq
$ yarn top
$ yarn application -kill
$ yarn node -list
$ yarn logs
$ yarn rmadmin refreshNodes
$ yarb rmadmin -transitionToActive
$ yarn rmadmin -failover
Applications
MapReduce
- submit java classes for map/reduce stages
cat /test/log | grep "hadoop" \ sort | unique -c > output.txt- works with key-value pairs only
- I/O bound
- Java
Hadoop Streaming
- use any executable
$HADOOP_HOME/bin/hadoop jar $HADOOP_HOME/hadoop-streaming.jar -input mydirin -output mydirout -mapper /bin/cat -reducer /bin/wc- can use Python
Hive
- partition = part of table
- buckets = parts of partition
- managed table = by hive itself
- external table = managed by HDFS, points to HDFS dir. Can be AWS S3 or EMRFS. This is what I used
- Hive uses thrift protocol
Pig
- python-like, procedural, strange syntax
Spark
- book claims that largest known cluster is 8000 nodes
- win 2014 Daytona GraySort contest
- 100x speed vs map-reduce
- key optimizations: less shuffle; less I/O synchronization; RAM
- does not need hadoop
- Mesos supports Kafka and Elasticsearch
- each application provides its own YARN ApplicationMaster that negotiates resources
- RDD
- transformations = new RDD from old RDD
- actions = results of computation
- lazy. not running until action.
- read only
- distributed
- resilience = if data is lost, it is recomputed
- application = 1+ jobs managed by 1 driver
- job = tasks executed due to action
- stage = tasks executed in parallel
- task = work assigned to 1 executor/container
- driver = app program containing spark code, launches jobs in cluster. runs on different node than client. should run close to worker nodes.
- cluster manager = YARN, MESOS, spark
- executor = JVM process
- spark context = contains details on cluster, addresses, configs. connects to different systems like YARN/HDFS.
- spark-submit requires spark context to be manually created.
- client mode = driver runs on client (default)
- cluster mode = driver runs on worker node
$ /spark-submit -status <submission-id>
- Spark JDBC server so that 3rd party apps can connect to Spark. need to start manually this process.
$ beeline -u jdbc:hive2://localhost:10000pointing to where spark JDBC server runs
- Spark SQL
- DataFrames
- Schema aware makes to store it more efficiently
- can register UDF to context then call it in SQL
- Users RAM and CPU
- disk, i/o, network is important but not utilized in scheduler
- Spark Executor = YARN container
- Stage = tasks without shuffling
- joins with inputs co-partitioned does not have big shuffle
- broadcast variables are per Node not container

Sqoop
- “SQL for Hadoop” = sqoop
- creates map jobs
- haddop noed communicate with external db
- has free form sql
- has partitioning, uses pk or any column
- has where condition
- HDFS -> RDBMS use staging table to avoid corruption, use batch export to avoid single row inserts
- Sqoop2 adds: separate server; no need to run client; db connections admin config.

Flume
- collect from data streams to HDFS
- keeps metadata in Zookeeper for resiliency
- agent JVM service, source -> channel (intermediary queue, buffering, durable or non-durable storage) -> sink
- event = payload delivered by Flume = body + headers = e.g. log record
- topologies of multiple agents, sources, sinks
- usually Avro format
- simple config, auto reloaded
- specify address + port of source
- 1 agent at source “agent” + 1 agent at destination “collector”
- use tail for access log in “agent”
Spout
- similar to Flume
- consume events, write them somewhere
- for Kafka
- stores checkpoints in Zookeper
Oozie
- DAGs
- odd syntax, XML